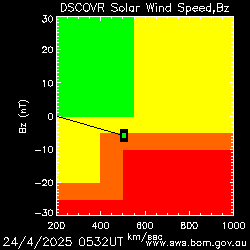
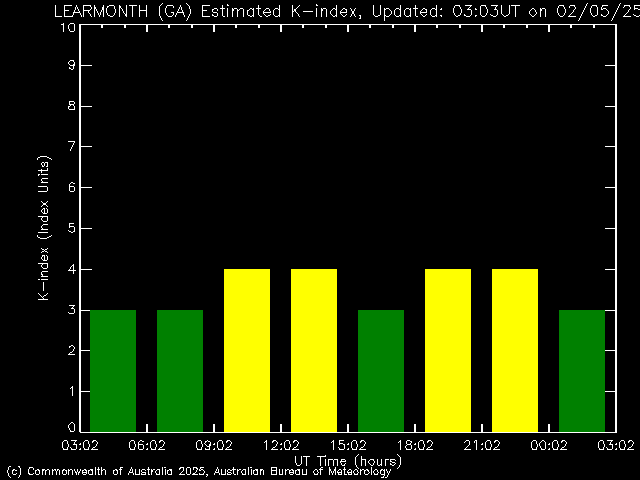
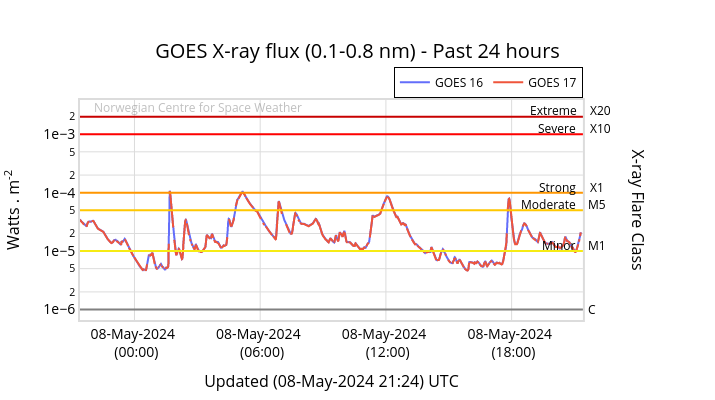
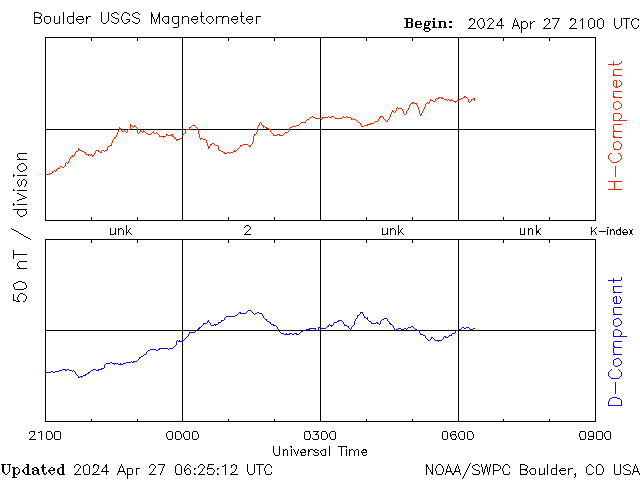


◄ Treść dostępna po zalogowaniu. ►
Trwa zbiórka darowizn na utrzymanie serwisu, więcej informacji po prawej stronie..


W marcu zebraliśmy:
Szybka wpłata anonim.
z czego cała reszta czytelników spoza grupy VIP: 0.0%


 Słońce On-Line
Słońce On-Line
 W ciągu 20 godzin Słońce wygenerowało 13 silnych r...
W ciągu 20 godzin Słońce wygenerowało 13 silnych r...
 Ostrzeżenia meteorologiczne i hydrologiczne oraz p...
Ostrzeżenia meteorologiczne i hydrologiczne oraz p...
 Geomagnetyzm Ziemi
Geomagnetyzm Ziemi
 Burza geomagnetyczna osiągnęła w niedzielę poziom...
Burza geomagnetyczna osiągnęła w niedzielę poziom...
 Słońce – Duży wyrzut plazmy na wschodzie
Słońce – Duży wyrzut plazmy na wschodzie
 USA – Trzęsienie ziemi o magnitudzie 4.8 w p...
USA – Trzęsienie ziemi o magnitudzie 4.8 w p...
 Słońce – Magnetogram ogromnej plamy 3615 z o...
Słońce – Magnetogram ogromnej plamy 3615 z o...
 Słońce – Średniej siły strefa magnetyczna wystąpi...
Słońce – Średniej siły strefa magnetyczna wystąpi...
 =Dział pomiarów=
=Dział pomiarów=
 Hualien, Tajwan – Wystąpiło największe od 25...
Hualien, Tajwan – Wystąpiło największe od 25...
 Słońce – Trzy bardzo silne rozbłyski klasy M...
Słońce – Trzy bardzo silne rozbłyski klasy M...
 Instytut Maxa Plancka opracował urządzenie do wykr...
Instytut Maxa Plancka opracował urządzenie do wykr...
 Niezwykła natura
Niezwykła natura
 Słońce – Bardzo silny rozbłysk klasy M5.5 na...
Słońce – Bardzo silny rozbłysk klasy M5.5 na...
 Aktywność Słońca w ostatnich siedmiu dniach
Aktywność Słońca w ostatnich siedmiu dniach
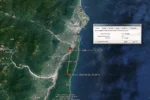 Tajwan – Silne trzęsienie ziemi w Hualien sp...
Tajwan – Silne trzęsienie ziemi w Hualien sp...
 Średniej siły oddziaływania magnetyczne wystąpią 6...
Średniej siły oddziaływania magnetyczne wystąpią 6...
 Japonia – Aktywność sejsmiczna od 2022 roku...
Japonia – Aktywność sejsmiczna od 2022 roku...
 Polska – Rząd będzie walczył ze śmieciami za...
Polska – Rząd będzie walczył ze śmieciami za...
 Licznik Geigera-Müllera – Stały pomiar promi...
Licznik Geigera-Müllera – Stały pomiar promi...
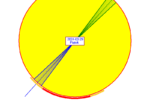 Słońce – Średniej siły strefy magnetyczne wystąpią...
Słońce – Średniej siły strefy magnetyczne wystąpią...